
Motivations
Artifical intelligence, and more generally machine learning, can often be considered as a black box. As parameter count increases and connections grow exponentially, it becomes harder to formally describe the inner workings of the system, and to extract useful insights from its training. This property is called “explainability”, and it is one of the area of focus of a research group at the Section of Mathematics of the University of Geneva, led by Sylvain Sardy. In their work, they use sparse models, i.e. models that have only few non-null weights, to easily explain the behavior of AI systems.
As part of their research, they have developped multiple techniques and algorithms. However, these algorithms are hungry in computing resources, and can sometimes take weeks to complete. For this reason, they have partnered with the Arc School of Engineering of Neuchâtel. As part of my Bachelor’s thesis, I was tasked with developping efficient and massively parallel software that implements the group’s statistical techniques and machine learning algorithms, in order to speed up their research.
Implementation
In order to guarantee a minimal level of parallelization, the different algorithms and techniques were all built using PyTorch’s tensor system. Tensors are data structure, similar to multi-dimensional matrices, that are efficently implemented in the C programming language. Along with Tensors, PyTorch offers an intuitive API to easily transfer all computations on the GPU, which guarantees a minimal level of parallelization.
Following PyTorch’s best practices, the different algorithms of the group were implemented using Tensors, and made to work on the GPU. This included multiple batteries of tests, and comparing performance between CPU and GPU versions of the algorithms.
The software is completely integrated with PyTorch, and acts as an extension (or plugin) to the framework. Every algorithm can be used with (or swapped out with) any other standard algorithm of the library.
Additionnaly, the algorithms were implemented using a modular architecture, which allows the implementation of custom CUDA kernels for maximum parallelization, and were accompagnied by documentation and examples on the interoperability of Python/PyTorch and C++/CUDA.
Results
The parallelization process allowed an average x9 speed-up between CPU and GPU versions. Even more when comparing with the original computation times achieved by the initial program built by the university (exact figures were not shared).
Additionnaly, the statistical results were analyzed to make sure they were valid. They were also compared to standard algorithms, such as SGD.
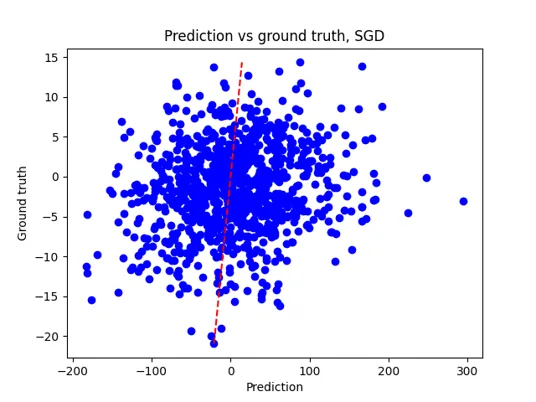
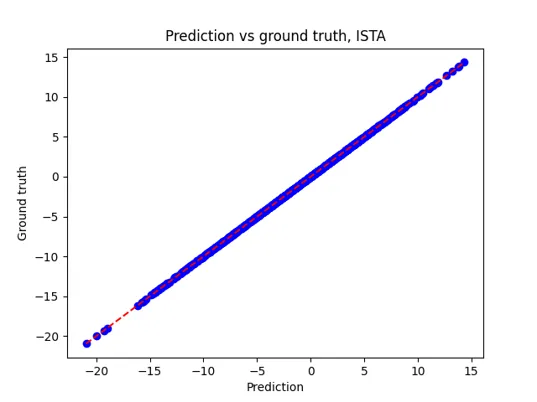
On the left, the standard SGD algorithm struggles with an almost random prediction, and high error rates. On the right side, the UniGE’s version of the ISTA algorithm performs with a very small mean error rate.
Future developments
Because of the modular architecture, the project allows the implementation of custom CUDA kernels. In the future, we could imagine implementing time critical sections of the algorithms directly with CUDA code tailored to the university’s chips, which would achieve maximal efficiency.